
Classifying articles via URLs
Lightweight language modeling

Today, I want to work through a small exercise in language modeling. A common NLP task for researchers working with news articles is some form of topic modeling. By getting a sense of what news stories are about, aggregated into a defined vocabulary of labels, researchers can make comparisons across groups (e.g., politics news versus financial news, or hard versus soft coverage). The question this raises is: What do we need to know about a news article to predict its topic?
Generally, this type of prediction relies on some amount of text from the news article—whether the entire article, its headline, or a summarized excerpt. Benchmarks show that these datasets, when paired with a well-suited model, can yield accurate labels. But obtaining such datasets presents challenges, which have become more pronounced in the past couple years.
The most obvious challenge is access, which is limited at a few levels of severity. At a minimum, an increasing number of news publishers are politely asking not to be scraped. Ben Welsh maintains a list of news publishers who block scraping from OpenAI, Google AI, or the Common Crawl. Out of 1,156 publishers, ~54% deny access to at least one of these crawlers. This has a knock-on effect for researchers who rely on datasets like Common Crawl, and it suggests a general aversion to third-party crawlers.
Then there are the hard limits to access. Some publishers block web scrapers entirely. And many have paywalls, which preclude even permitted scrapers from collecting much data.
Researchers are left stuck in a gray area. They are, one hopes, not attempting to collect troves of copyrighted news data to reproduce it elsewhere, or to train bots that pump out SEO-optimized blog posts. But they are scraping data that publishers would increasingly prefer not get collected. Researchers could move toward preexisting datasets, but those could produce stale observations. We're in need of a middle ground, one that relies on minimal data from news sites but provides researchers with fresh, real-world records.
(It's also worth mentioning that, even with perfect access, assembling a large-scale, high-quality news dataset is non-trivial. The varying site structures and article formats across news outlets demand custom parsing rules, which require significant tuning and iteration to work across varied page formats and asset types.)
A recent paper in Computational Communication Research caught my attention because of its focus on making more ML tools accessible with less compute and data required. In "URLs Can Facilitate Machine Learning Classification of News Stories Across Languages and Contexts", the authors propose a cost-effective, scalable solution to labeling political news. They use a form of "distant labeling" that works in three steps:
1. Identify relevant section taxonomy in news article URLs (e.g., "cnn.com/politics/"), and use those sections to label articles where present.
2. Count vectorize the text of remaining articles.
3. Use a Naive Bayes model to classify these vectors with a binary (politics/not politics) label.
There are, I think, some tensions inherent in this algorithm. The ML approach used here, as the authors acknowledge, will not produce optimal results: "our goal from the start was not to provide the best state-of-the-art method for news classification but to keep it as simple and resource-friendly as possible while obtaining a good-enough performance." But while the labeling pipeline uses straightforward, computationally cheap tools, it also introduces different kinds of resource requirements. In a heterogeneous dataset, identifying relevant and universally applicable section strings would likely involve intensive manual data examination. And while the URL first pass reduces the number of records that need to be fully processed, the pipeline still requires full article text---a more difficult dataset to collect as news organizations become more concerned about large language models.
An approach that addresses these concerns would eschew manual, rules-based labeling, and it would avoid the need for any article text, while still being computationally tractable (i.e., can run on a laptop). To do this, I wanted to take the authors' approach a step further: Is it possible to accurately classify news articles, solely from their URLs?
To skip ahead, the answer is yes (to some extent).
I tested this idea empirically with Rishabh Misra's news category dataset on Kaggle, which has a sample of ~210,000 HuffPost articles across 42 categories. The categories vary a lot in how many articles they contain, so let's focus on the top 12 (all with > 5,000 articles).
(As a sidebar - finding an appropriate benchmark dataset for this test ended up being quite difficult. There are plenty of benchmark samples for news text classification, but they often only contain article text and category labels - no URLs or other metadata. AG's corpus of news articles is a widely-used exception, but it has its own shortcoming for this task. Rather than article page URLs (which often have informative slugs about the content of the story), this corpus has links from RSS feeds (which are often just a string of characters that get redirected to an article page). It's not possible, in many cases, to resolve the canonical URLs, because the RSS links have rotted away in the years since data collection. So, while the news category dataset is limited to a single outlet, it does have the requisite metadata for this prediction task.)
I tested four models on this dataset. For one, I attempted to replicate the approach outlined in the CCR paper. However, HuffPost’s URL schema doesn’t contain category labels, so this model just uses a Naive Bayes classifier on TF-IDF vectorized article headlines. For the other three, I used BERT fine-tuned for classification, with variations of input text snippets: Headlines, brief excerpts, and URL paths.
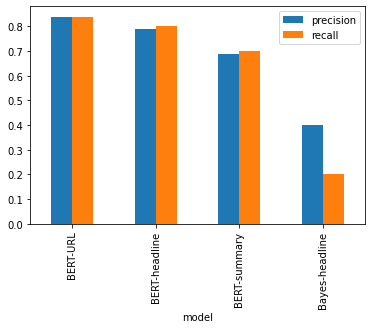
Looking at the performance graphs, the URL classifier does shockingly well - better than the more fully-fledged, written-for-humans text snippets from the articles. Relying solely on the paths of articles is not only a reasonable approach - it may be the optimal classification approach in some cases. From these results, the more text that gets provided as input, the worse it performs on the classification task. This holds true even with increased training epochs on longer text inputs, and for the Naive Bayes classifier.
There are obviously many factors to consider before rolling out this approach in a real-world application: How much information do the URLs in your sample contain? What model architecture will you use, and can you swing a longer training run that might better pick up on a larger text snippet? But URLs clearly offer an effective starting point.
Before wrapping up, I want to briefly discuss why this should work at all. News URLs often consist of some combination of hierarchical taxonomy, human-readable text, and unique record identifiers. Consider these examples, from The Verge and Politico:
https://www.theverge.com/24057063/neck-reading-light-review-book-night-dark
https://www.politico.com/news/magazine/2024/02/03/us-iran-proxy-war-00139445
Numerical identifiers are obviously less useful, but everything else conveys information about the topic and contents of the piece. And in some ways, this information can be a better signal than a larger snippet of text - it distills the crux of the piece into a few keywords, preemptively filtering out noise that might degrade model performance.
Does this suggest that we should all be running NLP on news article URLs every time we want to know something about them? I don't think so - there's a lot of variation in slug format, in the taxonomy of paths, and in how well they might map to what we want to know about the article they represent. But I do think this approach represents an interesting exercise in shrinking down language modeling. Rather than basing our predictions on every available scrap of text, we're paring down to smallest possible signal from source data. I think this represents a broader balance to strike within language modeling, finding the equilibrium between model sophistication and dataset size that makes these kinds of tasks both tractable and accessible.